





Das deutsche LBC-Korpus: Zusammenstellung und Anwendung
1. Einleitung
Die Forschungsgruppe Lessico multilingue dei Beni Culturali (LBC – «Mehrsprachiges Lexikon der Kulturgüter») wurde im Juli 2013 im Dipartimento di Lingue, Letterature e Studi Interculturali (LILSI[2]) der Universität Florenz eingerichtet. Daran schlossen sich Wissenschaftleren aus unterschiedlichen Universitäten und linguistischen Disziplinen (italienische, deutsche, englische, französische, portugiesische, spanische, russische, chinesische, türkische Sprachwissenschaft) sowie ein wissenschaftlicher Mitarbeiter der Digital Humanities an. Für die jeweiligen am Projekt beteiligten Sprachen wurde ein Arbeitsteam aus Spezialisten mit unterschiedlichem wissenschaftlichem Profil gebildet: Lexikologen, Lexikographen, Experten der Textlinguistik, der kontrastiven Grammatik, der Korpuslinguistik, der Übersetzungswissenschaft und der Fachsprachenforschung[3].
Hauptziele des Projektes sind u. a. die Erstellung einer Datenbank und eines Online-Fachwörterbuches der Kulturgüter mit thematischem Schwerpunkt „Florenz, die Toskana und die Renaissance“. Durch die Erstellung der Datenbank sollen Studien, Recherchen und weitere wissenschaftliche und angewandte bzw. praktische Aktivitäten über die Lexik der Kulturgüter in allen beteiligten Sprachen des Projekts ermöglicht werden. Das geplante multilinguale LBC-Wörterbuch soll eine im lexikographischen Panorama festgestellte Lücke, das Fehlen von ein- und mehrsprachigen Fachwörterbüchern zu diesem Thema, füllen.
In der ersten Arbeitsphase wurden für jede Sprache monolinguale Korpora erstellt, deren Aufbau auf der Basis von gemeinsam festgestellten Kriterien erfolgte: Grundkriterium für die Auswahl von Werken und Autoren war ihre Wichtigkeit für die Kunst und Kultur der Renaissance, wobei sowohl Übersetzungen als auch Originaltexte berücksichtigt wurden (vgl. Abschnitt 2). Anschließend wurde eine Korpusplattform realisiert und online gestellt, welche es den vielen in Frage kommenden Interessenten (Wissenschaftleren, jungen Forscheren, Studenten, Übersetzeren und Berufstätigen im Tourismusbereich) ermöglicht, auf wichtige Informationen im Gebiet der Kulturgüter zuzugreifen.
Die Korpusplattform bedient sich der free-source-Software NoSketch Engine, die den Benutzeren mehrere Funktionalitäten zur Verfügung stellt (u. a. die Recherche eines Suchwortes in seinem Kontext, die Sortierung der Belegstellen nach unterschiedlichen Kriterien, die Filterung der Texte nach Textsorten, Autoren sowie Zeitraum) und somit intra- und interlinguale Anwendungsmöglichkeiten, sowohl unter einer synchronischen als auch diachronischen Perspektive, bietet (vgl. Abschnitt 3).
Die Korpusplattform soll in einem nächsten Arbeitsschritt auch Parallelkorpora enthalten und als Datengrundlage zur Erstellung eines mehrsprachigen Internetwörterbuchs der italienischen Kulturgüter dienen (vgl. Abschnitt 4): Daraus soll sowohl die provisorische Stichwortliste als auch die Belegsammlung für die einzelnen Lemmata extrahiert werden (vgl. auch Buffagni, Flinz, Ballestracci 2020). Das angedachte LBC-Wörterbuch soll zunächst zweisprachig sein (Italienisch – Fremdsprache), ehe es anschließend als mehrsprachiges Werk erweitert wird. Der ausgewählte Ansatz für die Realisierung des lexikographischen Produktes wird der korpusbasierte quantitativ-qualitative Ansatz sein: Die Daten werden automatisch aus den Korpora extrahiert, aber sie werden qualitativ interpretiert (vgl. Lemnitzer, Zinsmeister 2015: 37).
Der vorliegende Aufsatz skizziert den heutigen Stand der Forschungsarbeit und bietet somit einen Überblick über die Zusammenstellung des deutschen LBC-Korpus und seine Anwendungs- sowie Erweiterungsmöglichkeiten.
2. Das deutsche LBC-Korpus
Die LBC-Korpusplattform ist eine multilinguale spezialisierte Korpusplattform und besteht aus monolingualen Korpora in mehreren Sprachen (Deutsch, Englisch, Französisch, Italienisch, Russisch, Spanisch), die sowohl Originaltexte als auch Übersetzungen enthält (vgl. Farina, Garzaniti 2013; Farina 2016; Billero, Martinez 2017; vgl. auch Abb. 1):
Hauptziel der LBC-Korpusplattform ist die Redaktion eines multilingualen Internetwörterbuches. Darüber hinaus möchte sie auch als Quelle für wissenschaftliche (u. a. sprach-, literatur- und kulturwissenschaftliche) Untersuchungen gelten und dem allgemeinen Publikum Texte zu einer besseren Kenntnis der italienischen Kulturgüter anbieten. Die Datenbank dient also nicht nur der LBC-Forschungseinheit zur Erstellung des Wörterbuches, sondern richtet sich darüber hinaus an externe Benutzeren wie Fachexperten in Kunstgeschichte, Italianistik u. ä., an professionelle Übersetzeren sowie an Didaktikeren der Fachübersetzung.
Von diesen Voraussetzungen ausgehend zielen die einzelnen LBC-Korpora darauf ab, die Lexik der Kulturgüter, insbesondere der italienischen, darzulegen. Aus diesem Grund wurde von Anfang an besondere Aufmerksamkeit auf die Sprache der Renaissance und der florentinischen Kunst und auf in dieser Hinsicht berühmte Werke und Autoren gelenkt (vgl. Abschnitt 2.1 und Abschnitt 2.2).
2.1 Textgenres
Das deutsche LBC-Korpus besteht – wie die anderen LBC-Korpora – sowohl aus Texten in deutscher Originalsprache als auch aus Übersetzungstexten aus den anderen Sprachen des Projekts (Italienisch, Französisch und Englisch[4]). Einige Texte standen in unseren Universitäts- oder Privatbibliotheken zur Verfügung und lagen in Papierfassung vor, andere wurden aus Online-Textarchiven heruntergeladen. Zu den verwendeten Online-Quellen gehören renommierte Textarchive wie beispielsweise das Deutsche Textarchiv, das insbesondere über Texte im PDF-Format verfügt, sowie das Gutenberg-Projekt, bei dem alle Texte im HTLM-Format zur Verfügung stehen. Die Texte in Papierfassung wurden gescannt, also in PDF-Dateien übertragen. Alle PDF-Dateien – sowohl diejenigen, die aus den Internetquellen stammen, als auch diejenigen, die aus einer Papierfassung entstammen – wurden durch ein OCR-Programm in Word-Format konvertiert, die Texte aus der Webseite des Gutenberg-Projekts direkt in eine Word-Datei kopiert[5]. Alle einzelnen Textexemplare sind formal bzw. sprachlich überprüft worden.
Zurzeit enthält das deutsche LBC-Korpus 762 Word-Dateien (insgesamt 1.183.019 Tokens)[6], die auf der Basis des Textgenres in drei Makrokategorien aufgeteilt werden können: populärwissenschaftlich, technisch-fachlich und literarisch (vgl. Tab. 1 und Abb. 2).
| Kategorien | absolute Häufigkeit |
| populärwissenschaftlich | 17.441 |
| technisch/fachlich | 526.984 |
| literarisch | 638.594 |
| Gesamt | 1.183.019 |

Tab. 1 und Abb. 2 zeigen, dass das im deutschen Korpus am meisten vertretene Genre das literarische ist (54%). Gut repräsentiert ist auch das technisch-fachliche Genre mit einem Prozentwert von 45%. Mit einem Prozentsatz von 1% sind die populärwissenschaftlichen Texte im deutschen LBC-Korpus am wenigsten vertreten.
Zu den literarischen Texten gehören Biografien, fiktionale narrative Werke und Essays. Ihre Verteilung wird durch Abb. 3 illustriert:
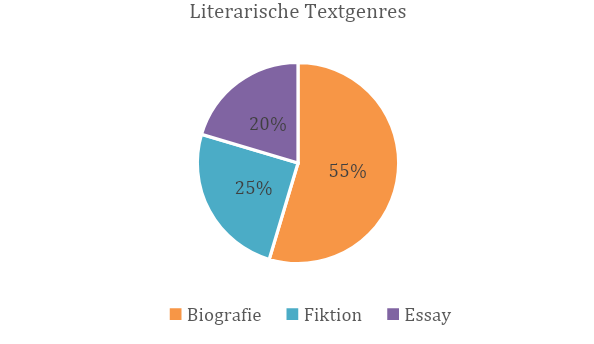
Wie Abb. 3 zeigt, ist die Kategorie Biografie mit einem Prozentsatz von 55% die größte, während die beiden anderen literarischen Kategorien – Fiktion und Essay – einen niedrigeren, etwa gleichwertigen Anteil aufweisen (25% bzw. 20%).
Zu den biographischen Texten gehören echte Biografien sowie Texte, die anderen Textsorten ähneln, z. B. Tagebücher und Reiseberichte. Diese Gruppe von Texten enthält in gleichem Maß Übersetzungstexte - z. B. aus dem Italienischen Das Leben des Benvenuto Cellini, florentinischen Goldschmieds und Bildhauer. Von ihm selbst geschrieben (2016)[7] von Benvenuto Cellini – oder aus dem Französischen – Reise in Italien (Rome, Naples et Florence en 1817) (1922) von Stendhal – sowie Originaltexte in deutscher Sprache wie bspw. Das Florenzer Tagebuch (1984) von Rainer Maria Rilke.
Zu den fiktionalen Texten zählen Novellen, Romane und andere literarische narrative Texte, die Florenz oder die Toskana zum Hauptthema oder als Handlungshintergrund haben. In dieser Kategorie sind nur Texte deutschsprachiger Autoren enthalten. Als Beispiel dafür gelten Florentiner Novellen (1984) von Isolde Kurz oder Florentinische Nächte (1969) von Heinrich Heine.
Auch zu den essayistischen Texten gehören nur Texte in deutscher Originalsprache, z. B. Stadt des Lebens (1905) von Isolde Kurz oder Geschichte der Renaissance in Italien (1891) von Jacob Burckhardt.
Die Kategorie der technisch-fachlichen Texte beinhaltet Fachtexte unterschiedlicher Bereiche: Kunst, Weingastronomie und Geschichte (vgl. Abb. 4):
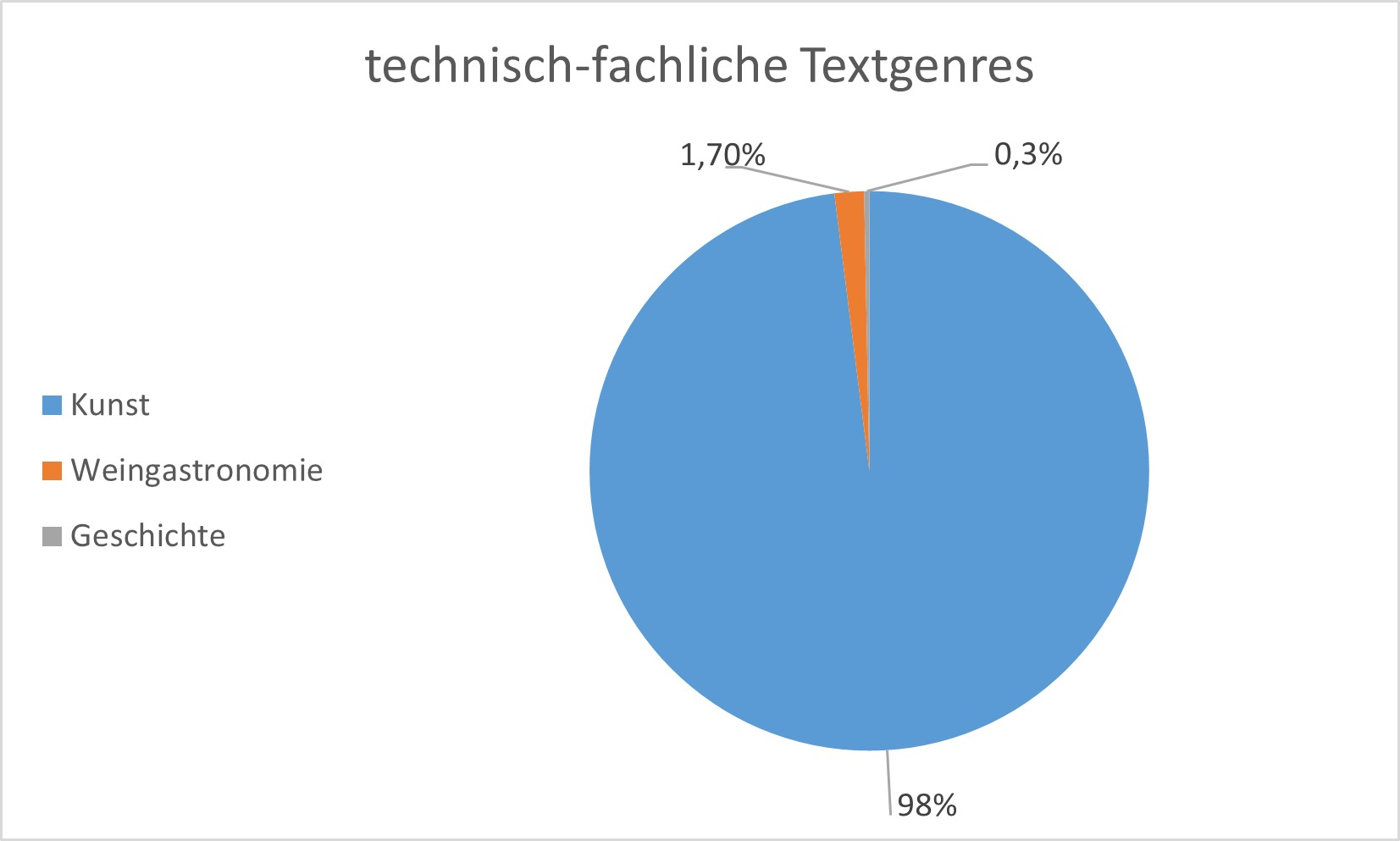
Einen großen Anteil haben Fachtexte der Kunst (über 500.000 Textwörter; 98%). Fachtexte der Weingastronomie und der Geschichte sind hingegen sehr wenig repräsentiert (ca. 11.000 Textwörter; ca. 2%).
Die Fachtexte zeigen weniger Varietät als die literarischen: Es handelt sich ausschließlich um Übersetzungen aus dem Italienischen, wie z.B. Der Traktat von der Malerei (1909) von Leonardo da Vinci, Kleinere kunsttheoretische Schriften (1877) von Leon Battista Alberti, Von der Wissenschaft des Kochens und der Kunst des Geniessens (2000) von Pellegrino Artusi und Geschichte von Florenz (1934) von Niccolò Machiavelli.
Unter den populärwissenschaftlichen Texten haben wir momentan nur einen einzigen Text: Es handelt sich um einen guten und relativ umfangreichen Reiseführer (17.441 Textwörter) in deutscher Originalsprache, Florenz. Perfekte Tage in der Toskana – Metropole (2016) von Ciccarelli, Jepson und Fisher[8].
Die Textauswahl wurde oft von der Verfügbarkeit der Texte selbst beeinflusst; trotzdem haben wir versucht, eine gewisse Varietät für alle Textgenres zu garantieren und diejenigen Textsorten zu bevorzugen, die besonders wichtig für die Endziele des Projekts waren. Soweit wie möglich wurden einige Kriterien – wie Autorschaft, Wichtigkeit des Werkes für die italienische Kultur und Kunst sowie ihre internationale Verbreitung und Rezeption – berücksichtigt. Bei einigen Textexemplaren hat die Genrezuschreibung dem Arbeitsteam besondere Schwierigkeiten bereitet. Als Beispiel dafür gilt das Werk von Giorgio Vasari (1966 [1568]), das den Gründungstext des Projekts darstellt, d.h. der Text, von dem die einzelnen Forschungsgruppen – nach Sprache geordnet – bei der Datenbeschaffung ausgegangen sind (deutsche Ausgabe: Leben der ausgezeichnetsten Maler, Bildhauer und Baumeister von Cimabue bis zum Jahre 1567, 2008). Diese Texte sind – wie andere Texte im Korpus – durch eine starke Textsortenmischung charakterisiert, weil ihr Stil zwischen fachlich-deskriptiv, biographisch-erzählend und kritisch-bewertend schwankt. Der Text wurde der Kategorie der technisch-fachlichen Genres zugeschrieben, wobei einerseits das Kriterium der überwiegenden stilistischen Merkmale, andererseits das Kriterium des Projektziels selbst eine Rolle gespielt hat. Dieses letztgenannte Kriterium hat auch die Auswahl der einzelnen im Korpus enthaltenen Autoren und Werke fortlaufend gesteuert (vgl. Abschnitt 2.2).
2.2 Autoren und Werke
Für die Auswahl der Autoren und Werke, die das LBC-Korpus ausmachen, haben wir uns für diejenigen entschieden, die für die Kunst und Kultur der Renaissance besonders repräsentativ sind. In diesem Sinne sind alle LBC-Arbeitsgruppen am Anfang des Projekts von Giorgio Vasari und seinen Vite (1550, 1568) ausgegangen, d. h. von einem Werk, das für die Kunst und Kultur der Renaissance grundlegend ist und zur Verbreitung des Mythos der italienischen Renaissance in den meisten Ländern Europas – so auch im deutschsprachigen Raum (vgl. Wackenroder 1991; Fiorillo 1798; vgl. auch Ballestracci, Buffagni 2016) – beigetragen hat. Diese Tatsache war für das gesamte Projekt auch deswegen ein Vorteil, weil das Werk von Giorgio Vasari in allen im Projekt miteinbezogenen Sprachen (Italienisch, Deutsch, Englisch, Französisch, Spanisch, Russisch und Chinesisch) vorliegt, was uns in der Zukunft auch ermöglichen könnte, ein Parallelkorpus der Vite für weitere Untersuchungen aufzubauen (vgl. Abschnitt 2.3 und Abschnitt 4). Andere italienische Autoren und Werke, die wir für unser Korpus ausgewählt haben, sind u. a. Opere Volgari (1849) von Leon Battista Alberti, Trattato della pittura (1651) von Leonardo da Vinci und Istorie Fiorentine (1971) von Niccolò Machiavelli. Soweit wie möglich wurde versucht, die gleichen Autoren in allen Sprachen aufzufinden.
Als grundlegend für das Projekt werden auch nicht-italienische Autoren betrachtet, die eine große Rolle bei der Verbreitung der italienischen Kultur der Renaissance in fremden Ländern gespielt haben: Dazu gehören z. B. Übersetzungstexte aus anderen Sprachen wie Wege zur Kunst (1897) von John Ruskin oder Texte in deutscher Originalsprache wie Die Geschichte der Renaissance in Italien (1891) von Jacob Burckhardt[9].
Eine weitere wichtige Gruppe stellen berühmte Autoren bzw. Literaten dar, die Reisen nach Italien gemacht haben und ein Tagebuch oder einen Reisebericht verfasst haben. Sie sind besonders wichtig, weil sie die italienische Kunst und Kultur mit fremden Augen beschreiben und somit zur Verbreitung der italienischen Kunst- und Kulturgüter vor allem im 19. Jahrhundert beitrugen, dies aber auch bis in die heutige Zeit gilt. Zu den literarischen Autoren des deutschen LBC-Korpus zählen berühmte Literaten wie beispielsweise Johann Wolfgang Goethe (Italienische Reise, 1997), Karl Philipp Moritz (Reisen eines Deutschen in Italien in den Jahren 1786 bis 1788, 2015), Fanny Lewald (Bilderbuch, 1992), Karl Eugen Gass (Pisaner Tagebuch. Aufzeichnungen/Briefe, 1961) und Stendhal (Reise in Italien (Rom, Naples et Florence en 1817), 1922).
Bezüglich aller Autoren wurden in den ersten Arbeitsphasen nur Fragmente aus ihren Werken ausgewählt, bei denen Florenz, die Toskana und die Kunst der Renaissance im Mittelpunkt stehen. In einer späteren Arbeitsphase sind die Kriterien erweitert worden: Einerseits wurde entschieden, nicht nur Florenz und die Toskana in Betracht zu ziehen, sondern ganz Italien, wobei der Schwerpunkt immer noch auf Kunst und Kultur bleibt; andererseits sollen nicht nur die Kunst und Kultur der Renaissance, sondern auch die Kunst und Kultur anderer Zeiten unter die Lupe genommen werden. In diesem Sinne ist das Korpus, das wir für die Erarbeitung der Konkordanzen (vgl. Buffagni, Flinz, Ballestracci 2020) benutzt haben und das wir hier beschreiben, das Abbild des Korpus zu einem bestimmten Zeitpunkt und kann durch folgende Abbildung dargestellt werden:
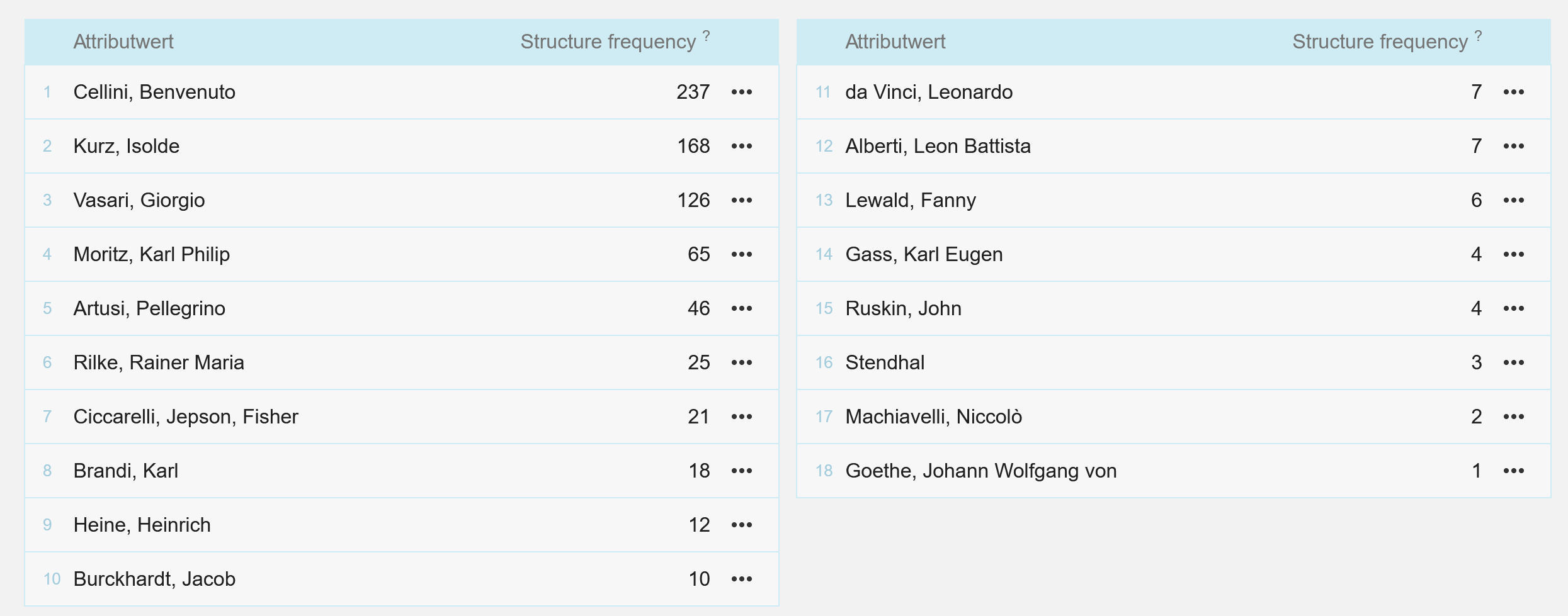
Durch Abb. 5 wird veranschaulicht, dass das deutsche LBC-Korpus insgesamt 18 Autoren umfasst: Von diesen sind zehn deutsche Autoren (Kurz, Moritz, Ciccarelli, Jepson und Fisher, Brandi, Heine, Burckhardt, Gass und Goethe), während die übrigen acht entweder italienische (Cellini, Vasari, Artusi, Alberti, da Vinci und Machiavelli) oder Autoren aus anderen Sprachen sind, wie Stendhal (Französisch) und Ruskin (Englisch) (vgl. Abb. 6).

Abb. 6 zeigt, dass vom deutschen LBC-Korpus Übersetzungstexte aus einigen Sprachen des Projekts (z. B. Spanisch, Russisch und Chinesisch) noch ausgeschlossen bleiben; diese sollen in den nächsten Arbeitsphasen in Betracht gezogen werden. In seinem aktuellen Zustand bietet allerdings das deutsche LBC-Korpus Texte, die eine relativ reiche diachronische Variation garantieren, da die gesammelten Texte zwischen 1400 und 2016 verfasst bzw. veröffentlicht wurden (vgl. Abb. 7).
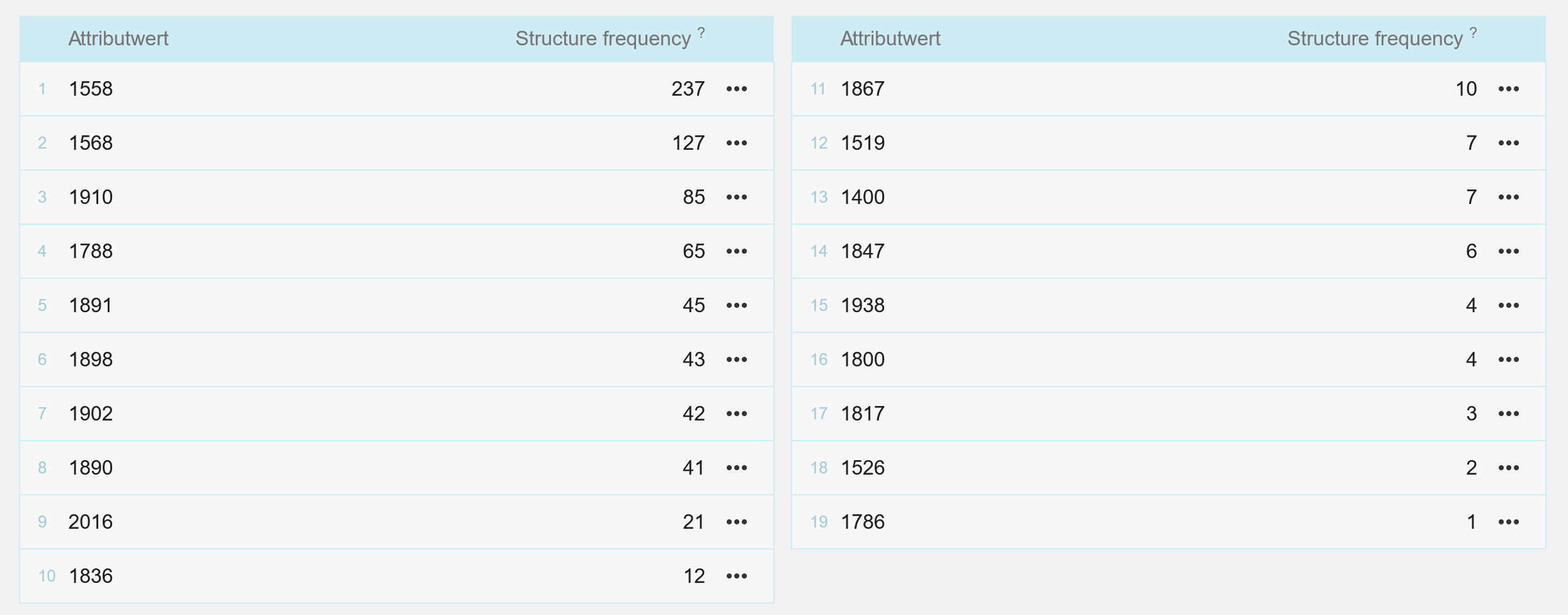
Zwar ist das deutsche LBC-Korpus unter verschiedenen Aspekten einiger Bilanzierungen bedürftig, es zeigen sich aber auch viele Aspekte, für die die Bewertung des Arbeitsstandes positiv ausfällt (vgl. Abschnitt 2.3).
2.3 Zwischenfazit
Zusammenfassend zielt die LBC-Korpusplattform neben der Redaktion eines multilingualen Internetwörterbuches darauf ab, bedeutungsvolle Texte über die italienischen Kulturgüter bereitzustellen. Somit bietet sie eine offen zugängliche Quelle für sprach-, literatur- und kulturwissenschaftliche Untersuchungen.
Wie aus dem Abschnitt 2.1 zu ersehen ist, gehört etwas mehr als die Hälfte der im Korpus enthaltenen Texte literarischen Textgenres an, während nahezu die Ganzheit der übrigen Texte den technisch-fachlichen Genres zugehörig und lediglich ein minimaler Teil der populärwissenschaftlichen Sparte zuzuordnen ist. Eine solche Zusammensetzung könnte bei einer ersten Betrachtung als nicht ganz ausgeglichen erscheinen, indem der Bereich Literatur als zu gewichtig gelten könnte. Diesem Eindruck kann man zunächst entgegenstellen, dass die gegenwärtige Konstitution der Datenbank auch genetische Gründe hat: Die meisten literarischen Texte standen in prestigeträchtigen und leicht zugänglichen Internetarchiven zur Verfügung, während dies bei vielen technisch-fachlichen Texten nicht der Fall war. In der ersten Arbeitsphase erschien es daher sinnvoll, mit der Sammlung von literarischen Texten zu beginnen. Die aktuelle Struktur der Datenbank, die, wie hervorgehoben, die Situation des Korpus in einem bestimmten Moment wiedergibt, entspricht also zuerst dieser Vorgehensweise.
Die getroffene Entscheidung zeigt sich aber auch aus einer anderen Perspektive als gelungen. Zu den literarischen Texten des deutschen LBC-Korpus ist zunächst zu vermerken, dass sie sich durch ihre Vielfältigkeit auszeichnen: Sie bestehen überwiegend aus Biografien, während der restliche Teil sich aus der Summe von fiktionalen und essayistischen Textgenres ergibt. Den Biografien kommt dabei eine ausgeprägte Bedeutung zu, denn zu ihnen wurden auch Reisetexte hinzugezählt. Wie im Falle von anderen in der Datenbank vertretenen Sprachen (z. B. Französisch) spielen Reisebeschreibungen und Reiseberichte quantitativ und qualitativ eine besondere Rolle für die Zwecke des deutschen LBC-Korpus: quantitativ, weil sie (vgl. Abschnitt 2.2) einen gewichtigen Teil des Korpus bilden; qualitativ, weil sie die Perspektive von fremden Betrachtern den italienischen und im Speziellen florentinischen Kunstwerken gegenüber wiedergeben (häufig handelt es sich um Reisende aus dem 18. und 19. Jahrhundert, etwa der inkognito reisende Ministerialrat Goethe oder der unruhige Soldat Stendhal). Die Beschreibungen, die deutsche, französische und englische Schriftsteller und Künstler den italienischen Kunstwerken gewidmet haben, sind Dokumente der jeweiligen Zeit und Lebensweise der Verfasser; sie besitzen einen hohen literarischen Wert und haben weltweit zu der Rezeption des Italienbilds beigetragen. Sie haben letztlich zu der Konstitution eines regelrechten „Italienmythos“ geführt, der weitreichende Folgen in der europäischen und außereuropäischen Kunst und Kultur haben wird. Darunter ist auch Ruskins Wege zur Kunst (1897, Übersetzung aus dem Englischen) zu nennen. Die weiteren im Korpus vorkommenden Biografien, die die Lebensgeschichten der Künstler der Renaissance haben, präsentieren sich ihrerseits als „Nachzeichnung[en] des Lebenslaufs eines Menschen“ und sind einer älteren Epoche zuzuschreiben (etwa Vasaris Lebensbeschreibungen und Cellinis Autobiographie). Architektonische Bauwerke, Skulpturen, Gemälde, Fresken, Stuck figuren und Verzierungen werden beschrieben und jeweils nach den von den Autoren genannten Kriterien bewertet. Diese Werke beinhalten „Elemente[…] der Geschichtsschreibung und der Dichtung“ (Best 1994, 71) und enthalten insofern wertvolle geschichtliche Informationen. Beide Arten biographischer Textgenres besitzen einen unvergleichlichen kulturhistorischen Wert, indem sie Einsichten in die Entwicklung der Kunstbeschreibung sowie der Kunstgeschichtsschreibung in der Zeit zwischen dem 15. Jahrhundert und der Gegenwart liefern.
Den literarischen Textgenres zugeschrieben sind auch – unter der Unterkategorie der essayistischen Texte – moderne Klassiker der Kunstgeschichtsschreibung wie Burckhardts Geschichte der Renaissance in Italien (1891) im Korpus zu finden. Burckhardts Werk, das einen bedeutenden Einfluss auf andere im Korpus vorkommende Autoren hatte (z. B. Isolde Kurz), zeichnet sich dank der damals neu erworbenen wissenschaftlichen Erkenntnisse aus und bietet ein noch facettenreicheres Bild der Kunst der Renaissance. Stilistisch zeigt es einen vielfach differenzierten, schmiegsamen Wortschatz, der neben Fachtermini auch schöngeistige Merkmale aufweist.
Für in der Literaturwissenschaft als prototypisch geltende fiktionale Gattungen sind ferner die im Korpus enthaltenen Erzähltexte zu erwähnen, darunter Heinrich Heines Erzählung Florentinische Nächte (1969) und Isolde Kurzʼ Novellenzyklus Florentiner Novellen (1984). Die Stadt Florenz und die Lebensweise der dortigen Bevölkerung bilden häufig den Hintergrund der erzählten Geschichten, deren reiche Variationsbreite sich unter anderem darin ausdrückt, dass sie sich in vergangenen Zeitepochen (wie in Kurzʼ Novellen) oder in der Gegenwart (etwa in Heines Erzählung) abspielen können.
Unter den technisch-fachlichen Textgenres, die gänzlich aus Übersetzungen bestehen, ragen insbesondere Leon Battista Albertis Kleinere kunsttheoretische Schriften (1877) und Leonardo da Vincis Traktat von der Malerei (1909) heraus: Der erstere bedeutet einen wichtigen Einschnitt in die damalige Kunstgeschichtsschreibung, indem ein innovativer Fachwortschatz (Architektur, Skulptur und Malerei) eingeführt wird; der letztere stellt eine vertiefte Überlegung zu dem Wesen der Malerei dar, die sich gerade zu der damaligen Zeit neben der Poesie als ebenbürtige Kunst etablieren will (Gombrich 2000). Niccolò Machiavellis Geschichte von Florenz (1934) bildet den einzigen fachlichen Text geschichtlichen Inhalts, während Pellegrino Artusi Von der Wissenschaft des Kochens und der Kunst des Geniessens (2000) sich als alleiniger Text der Gastronomie widmet. In beiden Fällen handelt es sich um Werke von großem kulturellem Wert. Insofern erweisen sich auch die technisch-fachlichen Textgenres, die fast die Hälfte des Korpus ausmachen, als repräsentativ für eine breite Zeitspanne (von 1400 bis 1891), während zu den populärwissenschaftlichen Texten ein zeitgenössischer Reiseführer in deutscher Sprache, Florenz. Perfekte Tage in der Toskana – Metropole (2016) von Ciccarelli, Jepson und Fisher zählt.
Wie aus der obigen Ausführung deutlich geworden ist, vereint die größte Mehrheit der im Korpus vorkommenden Texten einen hohen stilistischen Wert, der die multilinguale Datenbank und das deutsche Korpus auszeichnet. Gerade der ausgeprägte Stil besitzt einen inhärenten Wert und ist insbesondere für die Kunstbeschreibung und -geschichtsschreibung relevant. Nicht zufällig stellt Reiners den „anschauungsleeren Lexikonstil“ dem „Wortlaut, wie ihn ein guter Prosaschreiber geschaffen hat“ entgegen, um zum Schluss zu kommen: „Kunstgeschichtliche Werke stellen Bilder des einen Stils [d. h. des anschaulichen, A. d. V.] dem anderen [d. h. dem Lexikonstil, A. d. V.] gegenüber, um die Eigenarten herauszuheben. Auch im Reich der Worte wird die Schönheit der großen Prosa am deutlichsten vor dem Hintergrunde des Durchschnittsstils[10] “ (Reiners 1991, 219f.).So verschieden die Texte untereinander auch sind, so reichhaltig erweist sich die große Mehrheit der im Korpus präsenten Texte. Unter einem qualitativen Gesichtspunkt gesehen ist das Korpus somit als adäquat zu den verfolgten Zwecken zu betrachten. Wie in Abschnitt 2.2 angekündigt, wird die Perspektive in den nächsten Arbeitsphasen noch räumlich (auf ganz Italien) und zeitlich (auf Kunst und Kultur anderer Zeiten) erweitert; die Konzentration auf die stilistische Qualität und auf die kulturgeschichtliche Bedeutung der Texte bleibt weiterhin bestehen.
Es sei ferner hinzugefügt, dass, nicht zuletzt aus der eigenen Textkonstitution, das Korpus eine sprachliche Fundgrube ist: Erste Untersuchungen, die nach unterschiedlichen Ansätzen durchgeführt wurden, haben gezeigt, dass sie zu ertragsreichen Erkenntnissen von zahlreichen sprachlichen (z. B. lexikalischen, syntaktischen, textuellen, übersetzungswissenschaftlichen, vgl. Abschnitt 3) Phänomenen führen[11].
3. Anwendungsmöglichkeiten
Die LBC-Korpusplattform ist mit den Funktionalitäten der NoSketch Engine-Umgebung durchsuchbar, d. h. man kann sowohl Wortlisten auf der Basis der absoluten Häufigkeit (Wörter, Lemmata, Tags etc.) mit der Funktion Wortliste extrahieren als auch einzelne Wörter/Lemmata in ihrem Kontext (Keywords in Context) untersuchen und Kollokations-Kandidaten mit der Funktion Collocations extrahieren (vgl. Kilgarriff et al. 2004; Kilgarriff et al. 2014). Die Ergebnisse können dann in einem intralingualen oder interlingualen Vergleich bewertet werden. Da Korpora ein großes wissenschaftliches und pädagogisches Potential haben können (vgl. Flinz 2020; Flinz, Katelhön 2019), sind beide Perspektiven in verschiedenen wissenschaftlichen und didaktischen Bereichen anwendbar: für die Übersetzungspraxis schon operierender Übersetzeren, für die Ausbildung zukünftiger Übersetzeren sowie für die DaF-Didaktik im Allgemeinen[12]. Darüber hinaus können die LBC-Korpora nicht nur für die Forschung und Lehre der Fachlexik, sondern auch für die Erforschung anderer grammatischer Phänomene benutzt werden. Einige dieser Anwendungsmöglichkeiten möchten wir im Folgenden illustrieren.
3.1. Intralinguale Analysen
Das deutsche LBC-Korpus besteht aus 1.180.704 Tokens (vgl. Abb. 8). Da es sich aber um ein Monitorkorpus handelt (Lemnitzer, Zinsmeister 2015, 140), kann es ständig ergänzt und erweitert werden.

Eine der möglichen Anwendungen ist die Erstellung von Frequenzlisten nach Lemmata (Abb. 9), die Informationen über die Okkurrenzen von lemmatisierten Wörtern im Korpus geben.
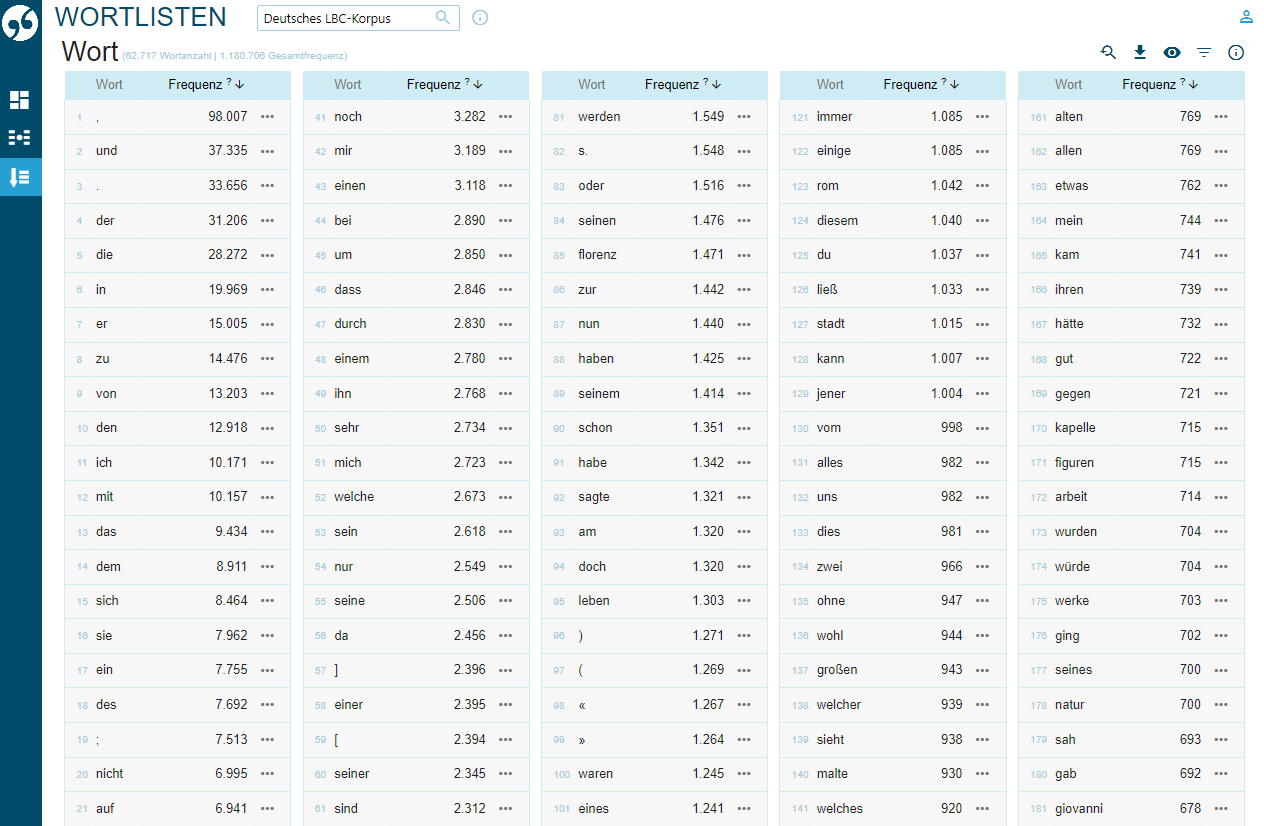
Daraus können z. B. die häufigsten Substantive, Verben, Adjektive entnommen werden:
- Substantive: Werk (2.183), Zeit (1.867), Bild (1.615), Florenz (1.471), Leben (1422), Kunst (1.368), Hand (1.342), Kirche (1.309), Rom (1.145), Haus (1.144), Papst (1.138), Herr (1.122) etc.
- Verben: sein (18.570)[13], haben (10.108), werden (7.982), sehen (3.132), können (3.059), sagen (2.612), lassen (2.276), wollen (2.216), machen (1.856), geben (1.814), kommen (1.806), malen (1.718), sollen (1.713), gehen (1.635), finden (1.369), stehen (1.304), arbeiten (1.275), müssen (1.260) etc.
- Adjektive: andere[14](3.555), groß (3.322), viele (2.854), schön (2.414), gut (2.285), alt (1.234) etc.
Wenn man z. B. nur die Substantive in Betracht zieht, sieht man sofort, dass am häufigsten Kunst-Fachwörter wie Werk, Bild, Kunst und Kirche sowie Städtenamen wie Florenz und Rom vorkommen. Bei Verben sind wie erwartbar Hilfsverben und Modalverben am häufigsten, aber auch typische Verben der Fachsprache, wie u. a. malen. Diese Anwendung kann die Sensibilität für Kollokationen[15] fördern, die ein besonders schwieriger und folglich fehleranfälliger Gegenstand einer (Fremd)Sprache sind (zu diesem Punkt vgl. auch Abschnitt 3.2).
Untersuchungen zum fachsprachlichen und standardsprachlichen Gebrauch eines Wortes sowie zu seiner diachronischen Entwicklung können ebenfalls gemacht werden, indem Textsorten, Autoren und Zeitangaben jeweils in der Suchmaske spezifiziert werden (Abb. 10):
Außer Wortlisten können auch einzelne Wörter im Korpus untersucht werden. Da Kirche ein Wort mit einer hohen Frequenz ist, sind auch die Kompositionsmöglichkeiten von Interesse. Mit der Suchoption *kirche können alle Komposita mit Kirche als Grundwort herausgefiltert werden:
Peterskirche (51), Hauptkirche (18), Servitenkirche (14), Domkirche (9), Paulskirche (7), Taufkirche (5), Andreaskirche (3), Weltkirche (3), Bettelordenskirche (2), Bischofskirche (2), Dorfkirche (2), Familienkirche (2), Franziskanerkirche (2), Kathedralkirche (2), Klosterkirche (2), Porkirche (2), Vorgängerkirche (2), Augustinerkirche (1), Barfüßerkirche (1), Benediktinerkirche (1), Gesetzeskirche (1), Gewölbekirche (1), Hauptporkirche (1), Hauskirche (1), Kapuzinerkirche (1), Karmeliterkirche (1), Kartheuserkirche (1), Kollegialkirche (1), Kuppelkirche (1), Madonnenkirche (1), Marienkirche (1), Markuskirche (1), Ordenskirche (1), Pfarrkirche (1), Unterkirche (1)
Man kann im Unterricht (mit Lernern unterschiedlichen sprachlichen Niveaus) sowohl über den Inhalt (die Bedeutung der Komposita) als auch über die Form der Komposita (Schreibweise mit und ohne Fugenelemente) reflektieren. Weitere Untersuchungen können dann eventuell durch weitere Online-Korpora ergänzt werden.
Darüber hinaus können die Konkordanzen[16] des Wortes Kirche Informationen zu seinem Gebrauch liefern wie z. B.:
- die mit Kirche bevorzugten Adjektive: achteckige Kirche, alte Kirche, bischöfliche Kirche, christliche Kirche, große Kirche, kleine Kirche, neue Kirche, römische Kirche, schöne Kirche, untere Kirche;
- die Genitiv-Verwendungen: u. a. Bild der Kirche, Bronzetür der Kirche, Chor der Kirche, Dach der Kirche, Eingang der Kirche, Fassade der Kirche, Grundriss der Kirche, Hauptaltar der Kirche, Hauptkapelle der Kirche, Haupttür der Kirche, Kapelle der Kirche, Kreuz der Kirche, Mittelschiff der Kirche, Querschiff der Kirche, Schiff der Kirche, Teil der Kirche, Tür der Kirche, Vorderwand der Kirche, Wand der Kirche;
- die bevorzugten Präpositionen: u. a. in der Kirche, inmitten der Kirche, innerhalb der Kirche, nach der Kirche, neben der Kirche, unterhalb der Kirche, von der Kirche, vor der Kirche, für die Kirche, in die Kirche;
- die präferierten Verben (Filter nach rechts): u. a. eine Kirche bauen, eine Kirche malen, eine Kirche vollenden, eine Kirche verfertigen;
- die gebildeten Eigennamen und ihre Varianten: u. a. Kirche del Carmine, Kirche della Pace, Kirche der Annunziata, Kirche der Madonna, Kirche des Heiligen Andreas, Kirche des S. Agostino, Kirche Ognissanti, Kirche San Giovanni, Kirche St. Andrea, Kirche von S. Agostino.
Kollokationsbewusstsein sowie Sensibilität für bestimmte grammatische Phänomene können somit bei den Deutschlernenden gefördert werden.
3.2 Interlinguale Analysen
Die in der LBC-Korpusplattform enthaltenen Korpora haben alle mehr als eine Million Tokens (Tabelle 2):
| Deutsch | Englisch | Italienisch | Französisch | Russisch | Spanisch | |
| Tokens | 1.183.019 | 1.912.340 | 1.386.086 | 3.918.894 | 1.934.713 | 1.164.117 |
Für jedes Korpus sind unterschiedliche Informationen enthalten, sodass man u. a. die Zahl der jeweiligen Texte pro Veröffentlichungsjahr, pro Autor, pro Textgenre (Abb. 11) entnehmen kann:

Die Informationen bieten dem Benutzer die Möglichkeit, Subkorpora aufzubauen, so dass auch textsortenorientierte interlinguale Studien gemacht werden können.
Auch Wortlisten aus vergleichbaren Korpora können für interlinguale Vergleiche benutzt werden, da mögliche Äquivalente identifiziert werden können (vgl. Tabelle 3):
| Substantive (D) | <-> | Substantive (I) |
| Werk (2.183) | cosa (4.925) | |
| Zeit (1.867) | opera (4.137) | |
| Bild (1.615) | tempo (2.358) | |
| Leben (1.422) | mano (2.328) | |
| Kunst (1.368) | figura (2.201) | |
| Hand (1.342) | anno (2.085) | |
| Kirche (1.309) | modo (1.939) | |
| Jahr (1.273) | parte (1.796) | |
| Rom (1.145) | città (1.686) | |
| Haus (1.144) | disegno (1.659) | |
| Papst (1.138) | chiesa (1.650) | |
| Herr (1.122) | uomo (1.626) | |
| Tag (1.095) | luogo (1.597) | |
| Stadt (1.095) | tavola (1.526) | |
| Meister (973) | Roma (1.442) | |
| Figur (945) | storia (1.425) | |
| Mann (918) | maniera (1.369) | |
| Künstler (903) | casa (1.346) | |
| Ding (900) | messer (1.253) |
Aus der Tabelle 3 können fremdsprachliche Äquivalente identifiziert werden: cosa/Ding, opera/Werk, mano/Hand, tempo/Zeit, figura/Figur, anno/Jahr etc. Die Bedeutung der restlichen Lexeme, z. B. Papst, können dann eventuell mit Hilfe der Kontexte (Abb. 12) erschlossen werden:
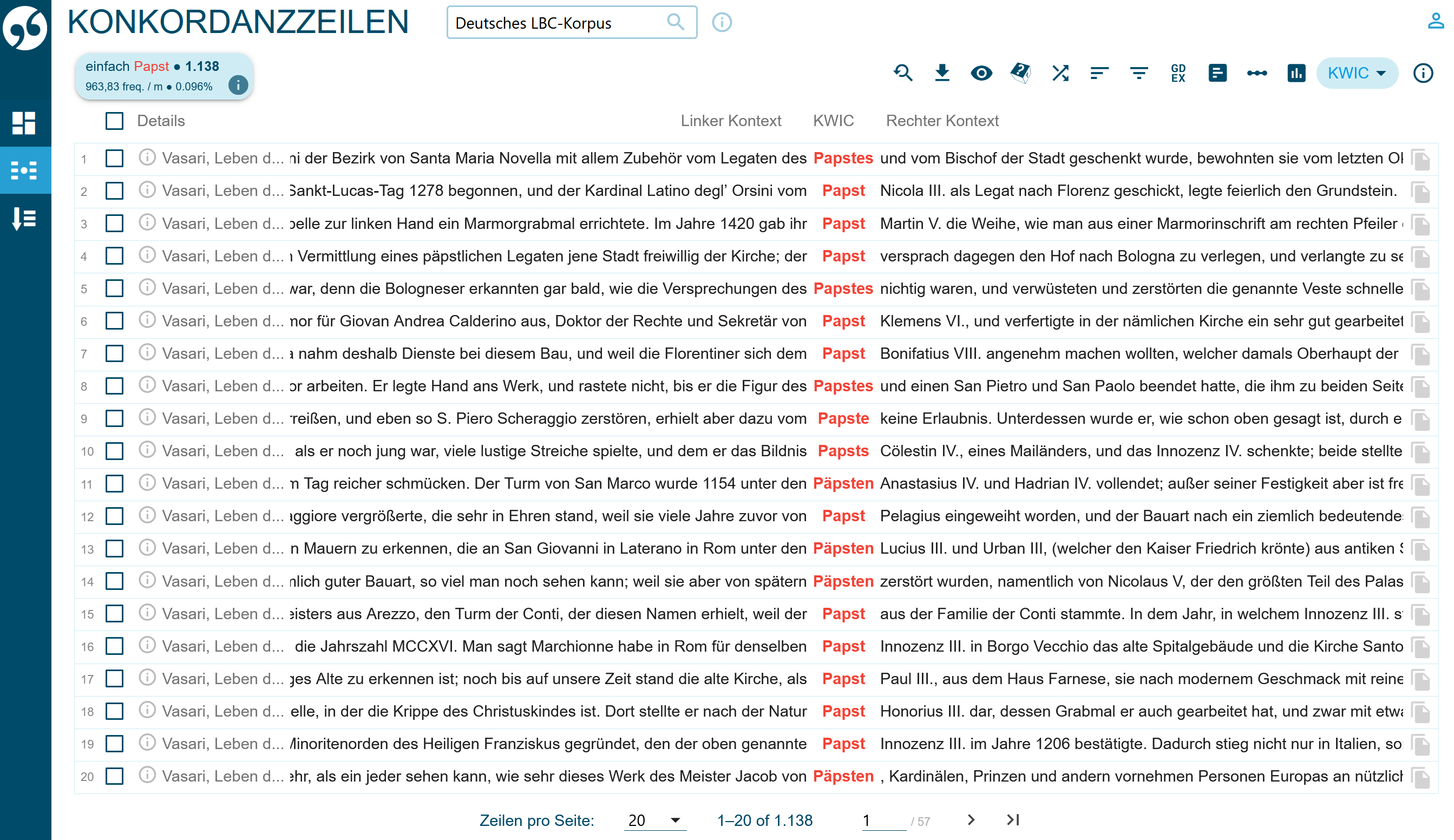
Das Suchwort Papst kann aber außer der KWIC-Darstellung auch in einer anderen Sicht geöffnet werden, z. B. als Text (Abb. 13):
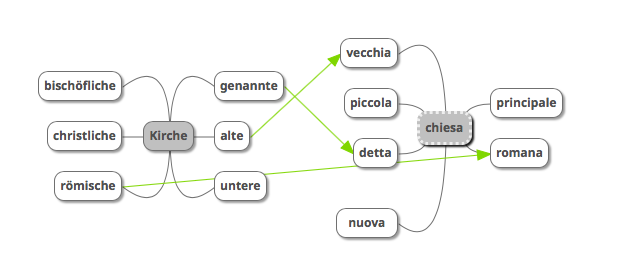
Eine weitere Anwendung, die eine bedeutende Rolle im DaF-Unterricht spielen kann, ist der interlinguale Vergleich von Kollokationen. Wenn wir weiterhin Kirche und die italienische Übersetzung chiesa als Beispiel nehmen und die adjektivischen Kollokationskandidaten extrahieren[17], können Äquivalenzbeziehungen (Abb. 14) erarbeitet werden:
- Kirche: genannte Kirche, bischöfliche Kirche, alte Kirche, christliche Kirche, untere Kirche, römische Kirche etc.
- Chiesa: detta Chiesa, nuova chiesa[18], chiesa principale, chiesa vecchia, chiesa romana, chiesa piccola etc.
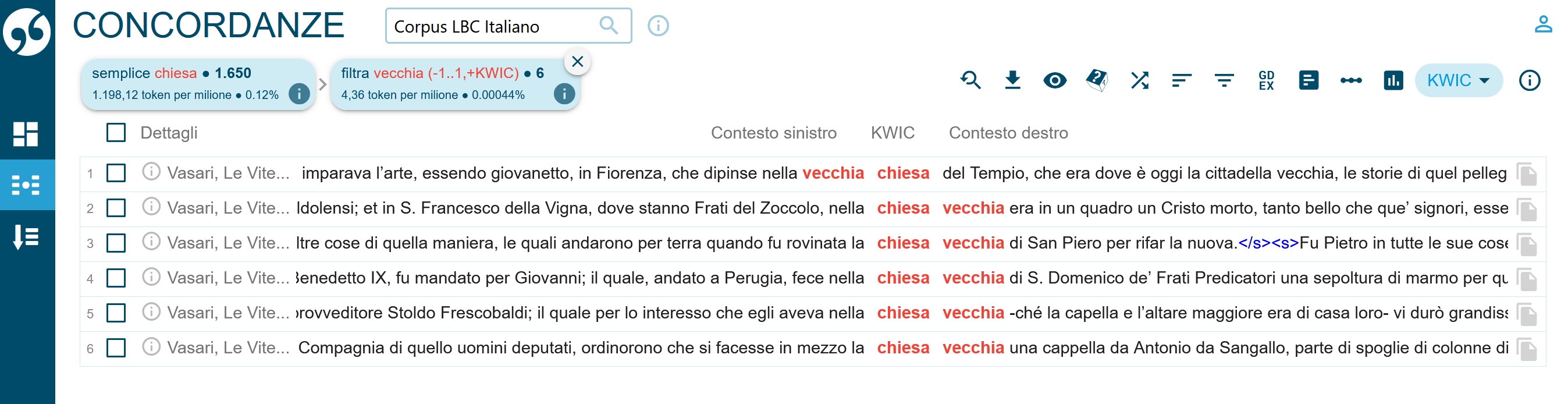
Die einzelnen Gruppierungen können auch in ihren Kontexten berücksichtigt und miteinander verglichen werden (Abb. 15):

Wie die oben angeführten Beispiele gezeigt haben, können die Lernenden mithilfe der integrierten Tools nach dem Aufbau einer gewissen corpus literacy (Mukherjee 2002, 179-180) auch selbst aktiv werden und im Korpus recherchieren.
4. Fazit und Ausblick
In diesem Aufsatz wurden die wichtigsten Merkmale des deutschen LBC-Korpus und einige von seinen Anwendungsmöglichkeiten beschrieben. Die hier gelieferte Beschreibung soll als das Bild eines work in progress betrachtet werden, denn sie bildet das deutsche LBC-Korpus zu einem bestimmten Zeitpunkt mit gewissen Eigenschaften ab. Das Korpus soll aber kontinuierlich mit qualitativ anspruchsvollen Texten erweitert werden, die sprachlich für alle anvisierten Benutzergruppen ein gutes Vorbild darstellen: Alle präsenten Textsorten sollen mit neuen Textexemplaren bereichert werden und zusätzliche Textsorten sollen hinzukommen; weitere zeitliche Schwerpunkte sollen hinzugefügt werden (nicht nur Kulturgüter der Renaissance, sondern auch spätere Kunstbewegungen) und diatopisch sollen weitere italienische Gebiete außerhalb der Toskana berücksichtigt werden. Auch die wissenschaftliche und die lexikographische Arbeit ist in progress, so dass sich alte und neue Phasen überlappen, wie es typisch für dynamische Online-Ressourcen ist (Klosa 2016, 29).
Trotz des Noch-im-Werden-Charakters der Arbeit beweisen die dargelegten Daten, dass das deutsche LBC-Korpus – wie die anderen LBC-Korpora – schon im heutigen Zustand für zahlreiche Forschungszwecke sowie didaktische Aktivitäten benutzt werden kann. Wie in Abschnitt 2 erläutert, sind sehr unterschiedliche Textgattungen bzw. -sorten sowohl aus einer synchronischen als auch von einer diachronischen Perspektive benutzt worden. Diese Zusammenstellung bietet den Benutzeren – ob es sich nun um Experten oder Laien handelt – eine breite Palette von Anwendungen (vgl. Abschnitt 3) sowie Reflexionen über Übersetzungsmöglichkeiten. Zusammenfassend eignet sich das deutsche LBC-Korpus für die Analyse von unterschiedlichen lexikalischen, morphologischen, syntaktischen, morphosyntaktischen und stilistischen Phänomenen aus vielerlei Perspektiven wie z.B.:
- aus textsortenbasierter bzw. -orientierter Perspektive;
- aus intralingualer und interlingualer Perspektive;
- aus übersetzerischer Perspektive (vgl. u. a. der Fokus auf die Dominanz an Italianismen in den gesammelten Übersetzungen, Farina, Billero 2018);
- aus kontrastiver Perspektive (Italienisch-Deutsch/Deutsch-Italienisch);
- aus diachronischer und synchronischer Perspektive.
Im Allgemeinen hoffen wir mit unserem Korpus allen Interessenten, die im Bereich der Kulturgüter forschen und arbeiten, ein hilfreiches Instrument zur Verfügung gestellt zu haben, von dem nützliche Hinweise auf kunst-, kultur- und textsortenbezogene linguistische Eigenschaften abgeleitet werden können. Darüber hinaus wurde konkret das deutsche LBC-Korpus schon als Primärquelle für die Erarbeitung der provisorischen Stichwortliste des geplanten LBC-Wörterbuches (vgl. Farina, Flinz 2020) und zur Herausfilterung der Konkordanzen benutzt (vgl. Buffagni, Flinz, Ballestracci 2020), die ein aktuelles Bild des status quo der Arbeit der Forschungsgruppe LBC-Deutsch liefern.
5. Literatur
Alberti L.B. 1849, Opere Volgari, Tipografia Galilei, Firenze.
Alberti L.B. 1877, Kleinere kunsttheoretische Schriften, Braumüller, Wien.
Artusi P. 2000, Von der Wissenschaft des Kochens und der Kunst des Geniessens, Hahn Verlag, Berlin.
Ballestracci S., Buffagni C. 2016, La traduzione dei ‘gerundi italiani’ in tedesco: un’analisi semantica esemplare, in Saraçgil A., Vezzosi L. (Hrsg.), Lingue, letterature e culture migranti, FUP, Firenze, 11-35.
Ballestracci S., Buffagni C., Flinz C. 2020, Das deutsche LBC-Korpus: Zusammenstellung und Anwendung, in Id., Corpus del Lessico dei Beni culturali in lingua tedesca / Das deutsche LBC-Korpus, FUP, Firenze. In pubblicazione, <http://corpora.lessicobeniculturali.net/de/>.
Belica C., Perkuhn R. 2015, Feste Wortgruppen/Phraseologie I: Kollokationen und syntagmatische Muster, in Haß U., Storjohann P. (Hrsg.), Handbuch Wort und Wortschatz, de Gruyter, Berlin-Boston, 201-225.
Best O.F. 1994, Handbuch literarischer Fachbegriffe. Definitionen und Beispiele, Fischer, Frankfurt.
Billero R., Nicolas Martinez M.C. 2017, Nuove risorse per la ricerca del lessico del patrimonio culturale: corpora multilingue LBC, «CHIMERA: Romance Corpora and Linguistic Studies», 4.2.
Brandi K. 1927, Die Renaissance in Florenz und Rom. Acht Vorträge von Karl Brandi, Springer Fachmedien, Wiesbaden.
Buffagni C., Flinz C., Ballestracci S. 2020, Das deutsche LBC-Korpus: provisorische Stichworliste und Konkordanzen, in Flinz C., Buffagni C., Ballestracci S., Deutsche Lexik der Kunst auf der Basis des Korpus LBC, FUP, Firenze. In pubblicazione, <http://corpora.lessicobeniculturali.net/>.
Burger H. 2015, Phraseologie. Eine Einführung am Beispiel des Deutschen, Erich Schmidt Verlag, Berlin.
Burckhardt J. 1891, Die Geschichte der Renaissance in Italien, Ebner & Seubert, Stuttgart.
Cellini B. 2016, Das Leben des Benvenuto Cellini, florentinischen Goldschmieds und Bildhauer. Von ihm selbst geschrieben, Karl-Maria Guth, Berlin.
Ciccarelli Roming C., Jepson T., Fisher T. 2016, Florenz. Perfekte Tage in der Toskana – Metropole, Taschenbuch Verlag, München.
Evert S. 2009, Corpora and Collocations, in Lüdeling A., Kytö A. (Hrsg.), Corpus Linguistics, de Gruyter, Berlin-New York, 1212-1248.
Farina A. 2016, Le portail lexicographique du Lessico plurilingue dei Beni Culturali, outil pour le professionnel, instrument de divulgation du savoir patrimonial et atelier didactique, rivista Publif@rum, 24.
Farina A., Billero R. 2018, Comparaison de corpus de langue « naturelle » et de langue « de traduction » : les bases de données textuelles LBC, un outil essentiel pour la création de fiches lexicographiques bilingues, in «JADT’18 Proceedings of the 14th International Conference on Statistical Analysis of Textual Data», UniversItalia, 108-116.
Farina A., Flinz C. 2020, LBC-Dictionary: a Multilingual Cultural Heritage Dictionary. Data collection and data preparation, in Euralex-Proceedings Volume 1. In pubblicazione.
Farina A., Garzaniti M. 2013, Un portale per la comunicazione e la divulgazione del patrimonio culturale: progettare un lessico multilingue dei beni culturali on-line, in Strategie e Programmazione della Conservazione e Trasmissibilità del Patrimonio Culturale, in Filipovic A., Troiano W. (Hrsg.), Edizioni scientifiche Fidei Signa, Roma, 500-509.
Fiorillo J. D. 1798, Die Geschichte der römischen und florentinischen Schule, Rosenbusch, Göttingen.
Firth J. R. 1957, Modes of Meaning, in «Papers in Linguistics 1934-1951», Oxford University Press, London, 190-215.
Flinz C. 2020, Vergleichbare Spezialkorpora für den Tourismus: eine Chance für den Fachsprachenunterricht, in Hepp M., Salzmann K. (Hrsg.), Sprachvergleich in der mehrsprachig orientierten DaF-Didaktik: Theorie und Praxis, Istituto Italiano di Studi Germanici, Roma, 133-151.
Flinz C., Buffagni C., Ballestracci S. 2020, Deutsche Lexik der Kunst auf der Basis des Korpus LBC. Firenze: FUP. In pubblicazione, <http://corpora.lessicobeniculturali.net/>.
Flinz C., Katelhön P. 2019, Corpora nella didattica del tedesco come lingua straniera. Proposte per l’insegnamento del linguaggio specialistico del turismo, in «EL.LE», 8.2, Volume monografico, 319-344.
Gass K. E. 1961, Pisaner Tagebuch. Aufzeichnungen / Briefe, Lambert Schneider Verlag, Heidelberg.
Goethe J.W. 1997, Italienische Reise, Deutscher Taschenbuch Verlag, München.
Gombrich E.H. 2000, La storia dell’arte raccontata da Ernst H. Gombrich, Leonardo Arte, Milano.
Hausmann F.J. 1984, Wortschatzlernen ist Kollokationslernen. Zum Lehren und Lernen französischer Wortverbindungen, in «Praxis des neusprachlichen Unterrichts», 31, 395-406.
Heine H. 1969, Florentinische Nächte, Artemis & Winkler Verlag, München.
Kilgarriff A. et al. 2004, The Sketch Engine, in Geoffrey W., Vessier S. (Hrsg.), Proceedings of the Eleventh EURALEX International Congress, Lorient, France July 6-10, 2004, Faculté des Lettres et des Sciences Humaines, Université de Bretagne, Lorient, 99–104.
Kilgarriff A. et al. 2014, The Sketch Engine: ten years on, in «Lexicography», 1, 7-36.
Klosa A. 2016, Der lexikographische Prozess im Projekt elexiko, in Hildenbrandt V., Klosa A. (Hrsg.), Lexikographische Prozesse bei Internetwörterbüchern, OPAL 1/2016, Institut für Deutsche Sprache, Mannheim, 29–38.
Kurz I. 1984, Florentiner Novellen, Phaidon, Essen.
Kurz I. 1905, Stadt des Lebens, Hermann Seemann Nachfolger, Leipzig.
Lemnitzer L., Zinsmeister H. 2015, Korpuslinguistik. Eine Einführung, Narr, Tübingen.
Lewald F. 1992, Bilderbuch, Urike Helmer Verlag, Frankfurt am Main.
Machiavelli N. 1934, Geschichte von Florenz, Phaidon, Essen.
Machiavelli N. 1971, Istorie Fiorentine, Sansoni, Firenze.
Moritz K.P. 2015, Reisen eines Deutschen in Italien in den Jahren 1786 bis 1788, e-artnow, o.O.
Mukherjee J. 2002, Korpuslinguistik und Englischunterricht. Eine Einführung. Peter Lang, Berlin u.a.
Reiners L. 1991, Stilkunst. Ein Lehrbuch deutscher Prosa, Beck, München.
Rilke R. M. 1984, Das Florenzer Tagebuch, Suhrkamp, Frankfurt am Main.
Ruskin J. 1897, Wege zur Kunst. Eine Gedankenlese aus den Werken von John Ruskin, Heitz und Mündel, Straßburg.
Stendhal 1922, Reise in Italien (Rome, Naples et Florence), Propyläen Verlag, Berlin.
Vasari G. 1550, Le vite de’ più eccellenti architetti, pittori, et scultori italiani: da Cimabue in sino à tempi nostri, Torrentino, Firenze. http://archiviovasari.beniculturali.it/index.php/1550-la-prima-edizione-de-le-vite/
Vasari G. 1966, Le Vite de' più eccellenti Pittori, Scultori et Architettori(erste Ausgabe 1568), S.P.E.S/Sansoni, Firenze.
Vasari Giorgio 2008, Leben der ausgezeichnetsten Maler, Bildhauer und Baumeister von Cimabue bis zum Jahre 1567, Directmedia Publishing, Berlin.
Vinci da L. 1651, Trattato della pittura, Jacques Langlois, Parigi.
Vinci da L. 1909, Der Traktat von der Malerei, Eugen Diederichs, Jena.
Wackenroder W.H. 1991, Herzensergiessungen eines kunstliebenden Klosterbruders, in Vietta S., Littlejohns R. (Hrsg.), Sämtliche Werke und Briefe, Historisch-kritische Ausgabe (erste Ausgabe 1797), Winter Universitätsverlag, Heidelberg.
6. Webseiten
Institut für Deutsche Sprache 2017, Deutsches Referenzkorpus / Archiv der Korpora geschriebener Gegenwartssprache
2017-I (Release vom 08.03.2017), Institut für Deutsche Sprache, Mannheim. PID: 10932/00-0373-23CD-C58F-FF01-3.
Lessico dei Beni Culturali, http://corpora.lessicobeniculturali.net/, 10.2020.
LBC-Korpusplattform, http://corpora.lessicobeniculturali.net/de/, 10.2020.
Deutsches Textarchiv, http://www.deutschestextarchiv.de/, 10.2020.
Gutenberg-Projekt, https://www.projekt-gutenberg.org/index.html, 10.2020.
Fußnoten
[1] Der vorliegende Beitrag wurde von den drei Autorinnen gemeinsam konzipiert und in seinen einzelnen Teilen im Detail besprochen. Sabrina Ballestracci hat Abschnitte 2.1 und 2.2 verfasst, Claudia Buffagni Abschnitt 2.3, Carolina Flinz Abschnitt 3. Bei den Abschnitten 1 und 4 sowie bei der Einleitung in den Abschnitt 2 haben alle Autorinnen gemeinsam zur Niederschrift beigetragen. Wir danken Katharina Müller und Anna Nissen für hilfreiche Fragen, Hinweise und den Austausch.
[2] Seit 2019 Dipartimento di Formazione, Lingue, Intercultura, Letterature e Psicologia (FORLILPSI).
[3] Dem deutschen LBC-Arbeitsteam gehören die Autorinnen des vorliegenden Aufsatzes an: Sabrina Ballestracci ist Expertin für Stilistische Textlinguistik und Kontrastive Linguistik, Claudia Buffagni für Übersetzungswissenschaft, Textlinguistik und Kontrastive Linguistik, Carolina Flinz für Lexikologie und Lexikografie, Korpuslinguistik und Fachsprachenforschung. Mitglied der deutschen Gruppe ist noch Katharina Müller (ehemalige DAAD-Lektorin an der Universität Florenz, ab 2018 Lektorin im Sprachzentrum der Goethe-Universität Frankfurt). In einigen Arbeitsphasen haben am Projekt auch der wissenschaftliche Nachwuchs und mehrere Praktikantinnen teilgenommen (vgl. Fußnote 5).
[4] Zum gesamten Projekt gehören auch andere Fremdsprachen, insbesondere das Spanische und das Russische; das schon online hochgeladene deutsche LBC-Korpus enthält jedoch keine Übersetzungstexte aus diesen Sprachen (vgl. auch Abb. 6 in Abschnitt 2.2.). Eine Korpuserweiterung in diesem Sinne ist eines der Ziele der nächsten Arbeitsphasen (vgl. Abschnitt 2.3 und Abschnitt 4).
[5] Für die Durchführung dieser ersten Forschungsphase ist die Arbeit des wissenschaftlichen Nachwuchses und von Praktikantinnen der Universität Florenz unentbehrlich gewesen. Dr. Benedetta Bronzini, Dr. Sara Congregati, Valentina Baldi, Domenica Barone, Delia Papandrea, Maria Chiara Susini, Clara Sabatino, Giulia Giannattasio und Lisa Bandinelli gilt hier unser besonderer Dank.
[6] Die Zahlen beziehen sich auf den Stand des Korpus am 31. August 2018 (vgl. auch Abschnitt 3.1). Seitdem wurde das deutsche LBC-Korpus intensiv erweitert; die neuen Texte, die bearbeitet wurden, sind jedoch noch nicht online verfügbar. Als das Korpus 1.000.000 laufende Textwörter erreichte, wurde es nicht mehr online inkrementiert, um die Arbeit an den Konkordanzen auf eine geschlossene Textsammlung zu stützen (vgl. Flinz, Buffagni, Ballestracci 2020). Diese Entscheidung wurde für alle Sprachen des Projektes getroffen.
[7] Von hier an beziehen sich die bibliographischen Hinweise auf die Ausgaben der Texte, die im Korpus enthalten sind.
[8] In einer ersten Arbeitsphase wurden auch andere Reiseführer in Betracht gezogen, die dann aber wegen des Mangels an Informationen zur angewendeten Sprache (z.B.: ob es eine Übersetzung oder ein Originaltext war) vom Korpus ausgeschlossen werden mussten.
[9] Das Werk von Burckhardt ist im deutschen LBC-Korpus noch nicht vollständig enthalten, weil die aus der PDF-Version konvertierte Word-Datei ziemlich unrein war, was bei der formalen und sprachlichen Revision große Schwierigkeiten bereitete.
[10] Mit „Durchschnittsstil“ meint Ludwig Reiners den typischen Lexikonstil, den er als abstrakt und „anschauungsleer“ kritisiert. Am entgegengesetzten Pol steht die große Prosa. Nach Ansicht des Autors leistet der „gute Prosaschreiber“ eine bedeutende Arbeit, die viel Vorstellungskraft und Weltkenntnis erfordert, um komplexe geistige Vorgänge anschaulich wiederzugeben und sie somit lebendig zu machen (Reiners 1991, 219).
[11] Dazu sind auch zahlreiche Abschlussarbeiten zu erwähnen, die in Florenz und in Siena verfasst wurden und Vasaris Text oder andere Texte des LBC-Korpus zum Thema hatten.
[12] LBC-Korpora können außerdem für weitere Zielsetzungen benutzt werden, wie beispielsweise lexikographische und diskurslinguistische Studien.
[13] Es ist uns aufgefallen, dass unter sein sowohl die Okkurrenzen des Hilfsverbs sein als auch des Possessiv-Adjektivs sein zu finden sind. Das kann auf Fehler beim automatischen Tagging zurückgeführt werden. Dieses Problem kann jedoch im Unterricht auch positive Auswirkungen haben, da die Lernende für polyfunktionale Einheiten sensibilisiert werden können, die sie dann autonom aus den Kontexten erschließen können.
[14] Die automatische Lemmatisierung von einigen Ausdrücken (anders, viel etc.) erfolgt fälschlicherweise mit dem Femininum.
[15] Der Terminus ‚Kollokation‘ wird in der Literatur unterschiedlich definiert. Zusammenfassend kann betont werden, dass sich zwei Auffassungen durchgesetzt haben: eine empirische (u.a. Firth 1957; Evert 2009; Belica, Perkuhn 2015), dessen Hauptkriterium die Frequenz ist und eine theoretische (u. a. Hausmann 1984, Burger 2015), die Kollokationen als lexikalische Einheiten in syntaktischer Beziehung (Hausmann 1984) oder mit einer gemeinsamen Bedeutung definiert. In diesem Artikel wird die These vertreten, dass beide Auffassungen für den DaF-Unterricht von Bedeutung sind.
[16] Die KWICs können mit der Option (Sort Left, Sort Right etc.) geordnet werden. Diese Option bietet die Möglichkeit, die Aufmerksamkeit auf bestimmte Eigenschaften der untersuchten Sprache zu lenken.
[17] Es wurde beispielhaft die Option range (-1 to 1) ausgewählt. Standardmäßig ist jedoch die Option (-5 to 5) eingestellt.
[18] Es wurden die häufigsten Verbindungen aufgelistet. Varianten wie chiesa nuova und principale chiesa sind auch im Korpus enthalten, jedoch weisen sie eine niedrige Frequenz auf.